こんにちは、Researcherの北山です。今回は自然言語処理技術を用いてAstrategyにおける顧客体験向上のための取り組みを行ったので、その内容を共有したいと思います。
本内容は弊社のTech Meetup #04でも発表した内容になりますので、ご興味のある方はそちらもご覧いただけますと幸いです。 自然言語処理とは、我々が日常のコミュニケーションで用いている言語(自然言語)を機械で処理する技術のことです。情報系の分野では単に言語というとプログラミング言語を連想する方も多いため、それと区別するために自然言語という用語が使われています。自然言語処理が活用されている事例としては、例えば以下のようなものがあります。
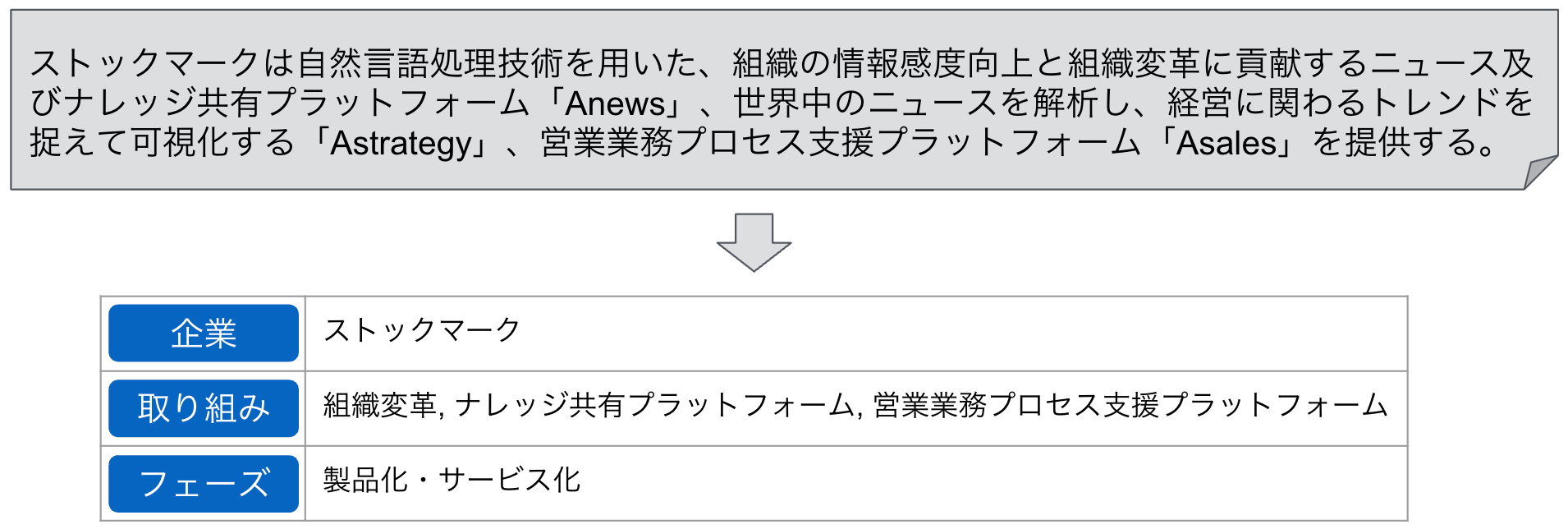
弊社では、そういった自然言語処理を活用し、ニュース記事内の情報を構造化することによって顧客体験の向上に取り組んでいます。例えば、以下の例ではニュース記事から主題企業とその取り組み、またそれがどのフェーズにあるのかといった情報を抽出して構造化しています。こうした情報を蓄積して構造化しておくことで、その後の分析や情報提供に活用することができます。
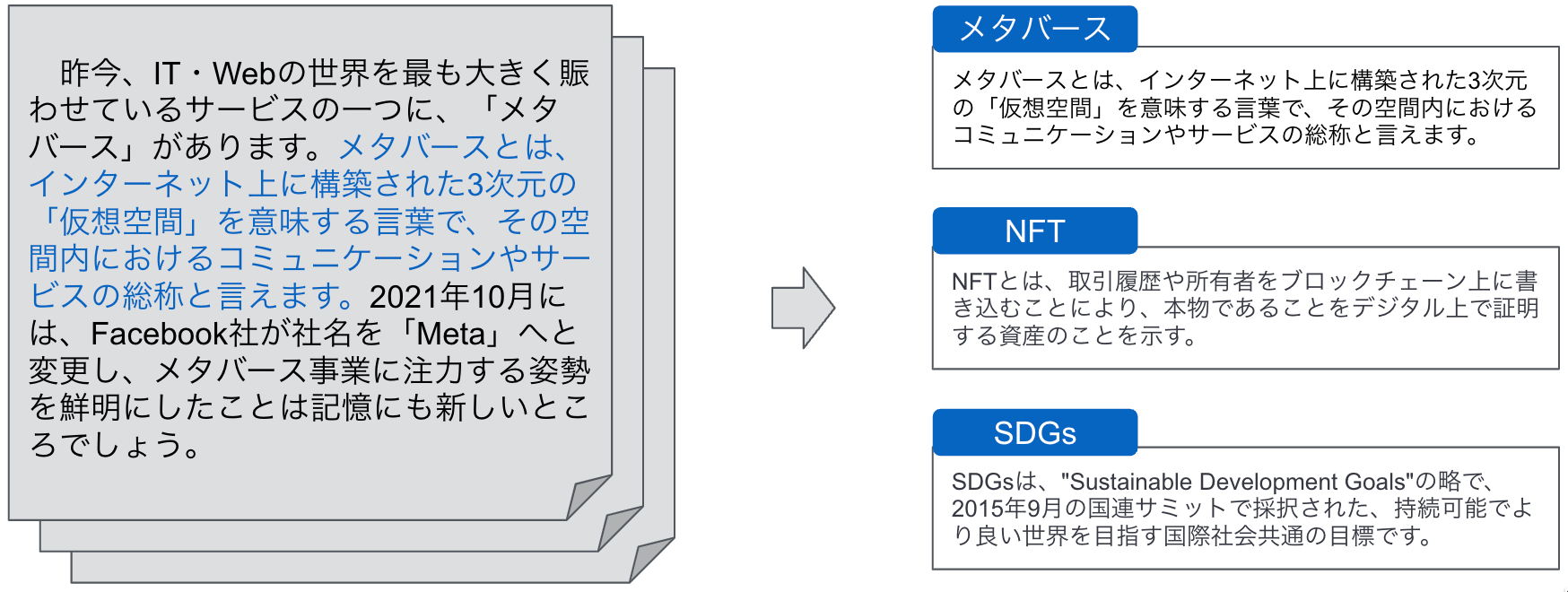
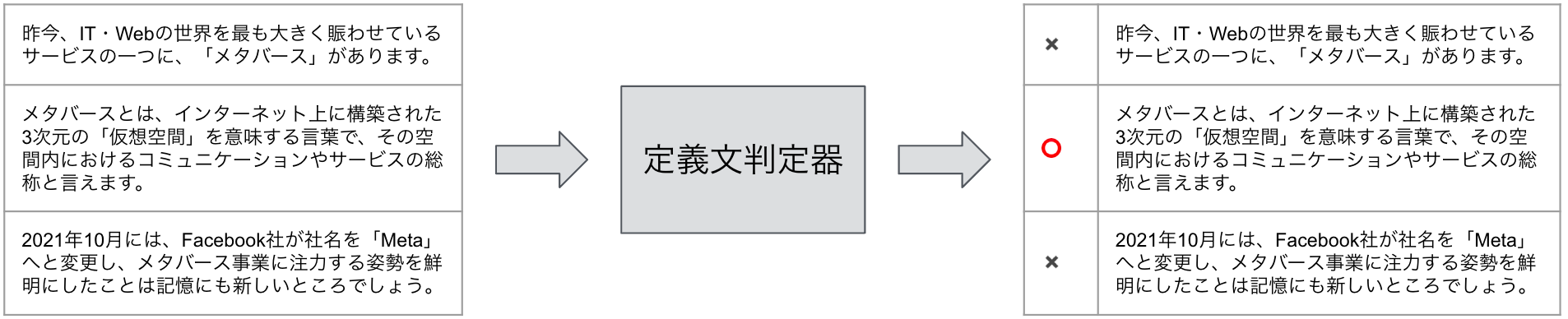
今回は構造化の一つとして、定義文抽出に取り組みました。ここでは、以下の図に示すようにニュース記事から単語の定義を説明している文(定義文)を抽出しています。
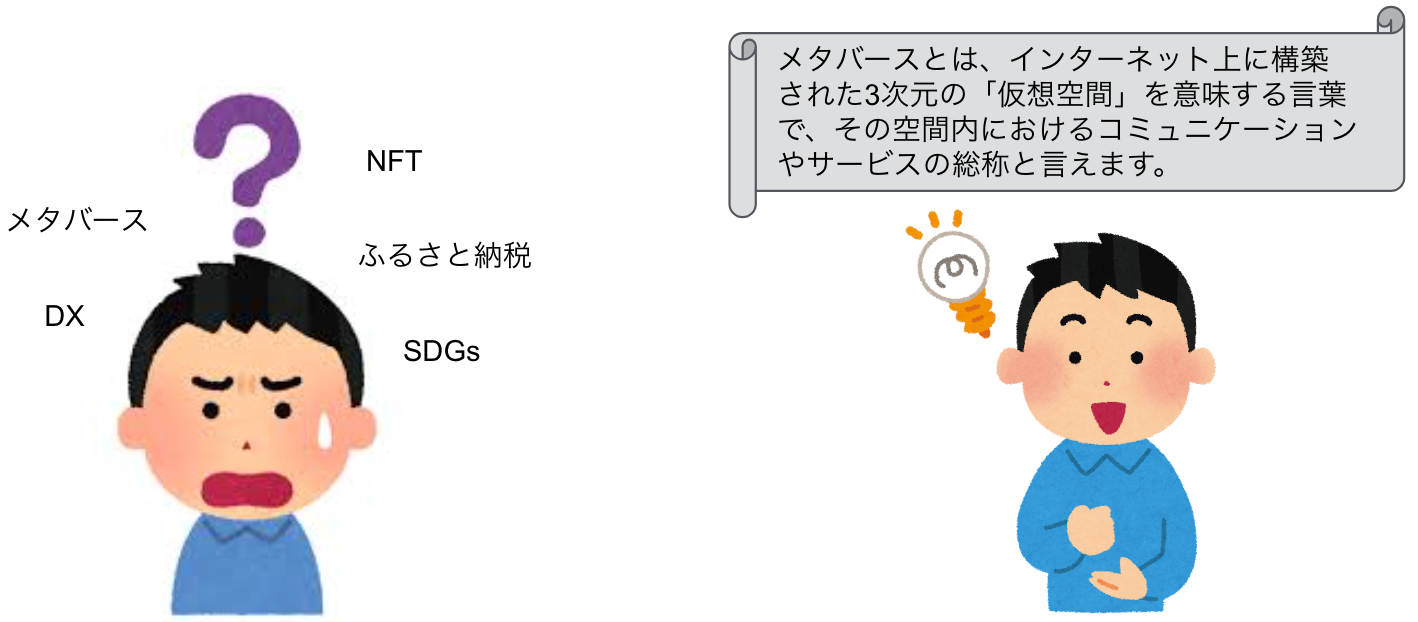
そもそも、なぜ定義文が必要になるのでしょうか?これまで、Astrategyを利用していただいているお客様がトレンドなどに分からない単語が出てきた際に、外部サービス(Google検索など)で調べなければならなかったり個別のニュース記事を見にいって中身を確認しなければいけなかったという課題がありました。定義文抽出によって予め用意された定義文をAstrategy内で提示することができれば、そういった課題を解決することができます。
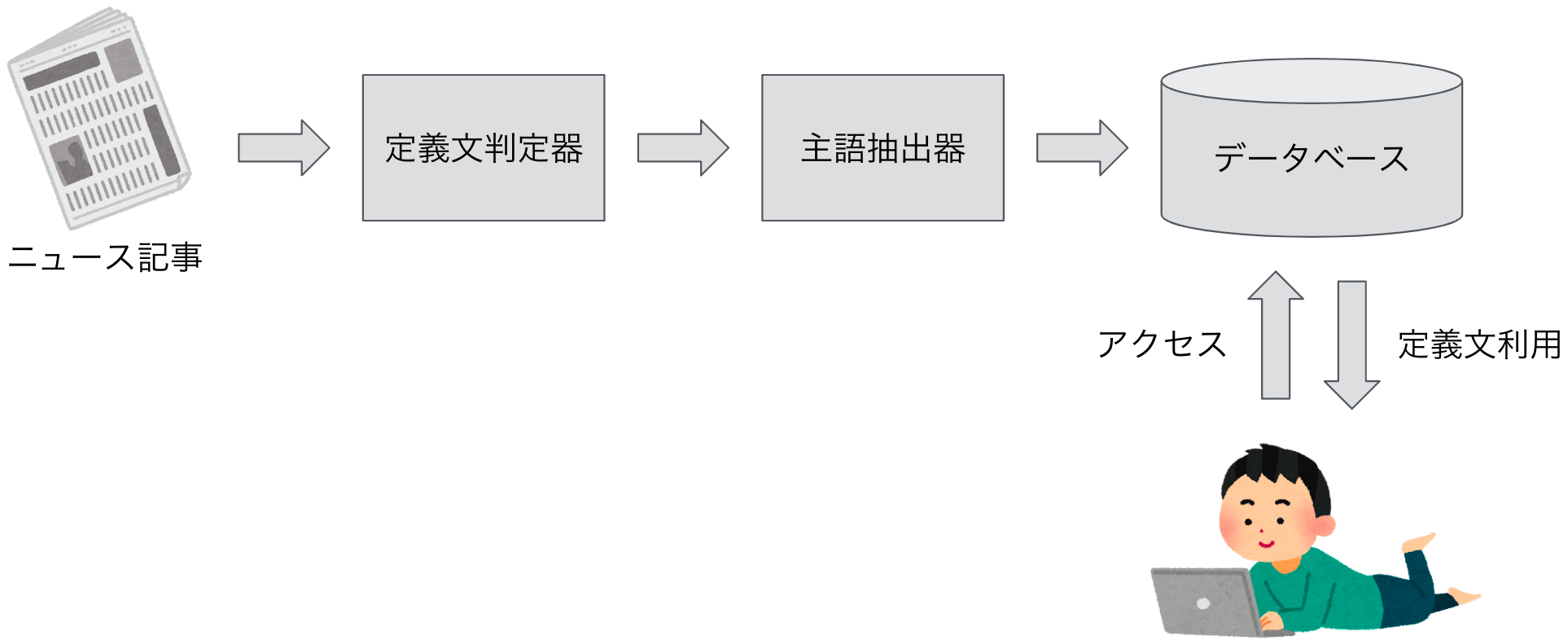
ここからは、実際の定義文抽出の流れについて説明します。以下の図のように、ニュース記事を定義文判定器と主語抽出器の2種類によって処理した後、抽出された定義文をデータベースに保存することによって構造化が行われます。そうして保存されたデータベースにアクセスすることによって、必要な時に定義文の情報を利用することができます。
2つの処理器についてもう少し詳しく解説すると、まず、定義文判定器ではニュース記事内の文章1つ1つを定義文であるか否かの2値に分類しています。こちらは、BERTという機械学習モデルを使用しています。BERTは大量のデータにより学習された大規模事前学習済みモデルであり、追加で用意したデータでfine-tuningすることにより様々なタスクを解くことのできる汎用モデルでもあります。今回は、社内で作成した定義文用のデータを用いて判別器を作成しました。
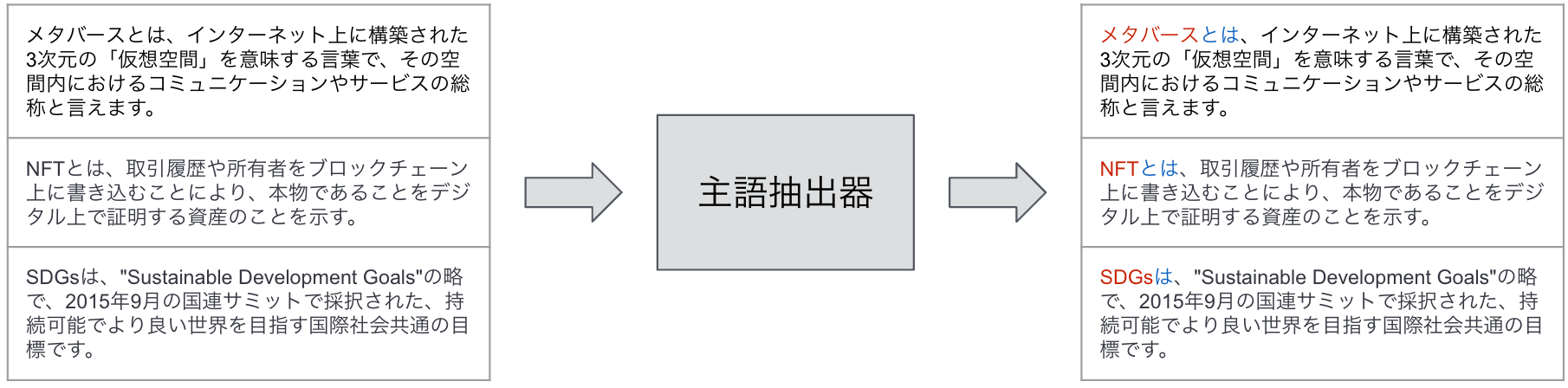
また、主語抽出器では定義文判定器によって定義文と判定された文に対して、主語部分を特定し抽出しています。こちらは、形態素解析という技術を用いています。形態素解析とは、文を単語単位に分割しそれぞれの単語に対して品詞情報などを付与することのできる技術です。その情報を用いて「複合名詞+は/とは」が出現する箇所を文中から検出し、複合名詞部分だけを抜き出すようなアルゴリズムによって主語抽出器を作成しました。
以下は定義文抽出によって獲得することのできた定義文の一例です。メタバースやNFTのような近年流行りの単語だけではなく、バスクチーズケーキやぴえん〇〇のようなマイナーそうなものまで幅広く抽出することができました。表示順は、検索している単語が文の主語と完全一致しているものを優先して表示しており、その中でも文の長さが長いものが上に来るようになっています。今後の製品上でのリリースに当たっては、お客様のニーズに合わせて優先して表示するべきメディアのソースなど、並べ替えに使用する情報を選定していく必要があります。 現在、抽出した定義文をAstrategy上のサービスに表示できるように開発を進めております。また、定義文の情報を活かした別の取り組み(文章要約やトレンド分析など)を進めることによって、新たな価値提供ができるのではないかと考えております。 [1] https://thebridge.jp/tag/astrategy [2] https://and-engineer.com/articles/YuORlxAAACAAKnUa [3] https://www.zenchin.com/news/content-11.php [4] https://prtimes.jp/main/html/rd/p/000003991.000003442.html [6] https://diamond.jp/articles/-/295882 [7] https://finance.yahoo.co.jp/news/detail/20220511-00935059-fisf-stocks [8] https://panora.tokyo/archives/43200 [9] https://prtimes.jp/main/html/rd/p/000000017.000060077.html [10] https://prtimes.jp/main/html/rd/p/000000023.000081780.html [11] https://prtimes.jp/main/html/rd/p/000000054.000025762.html [12] https://prtimes.jp/main/html/rd/p/000002374.000003670.html [13] https://japan.cnet.com/release/30613322/?ref=rss
[14] https://www.weeklybcn.com/journal/explanation/detail/20220517_191017.html [15] https://prtimes.jp/main/html/rd/p/000000191.000015685.html [16] https://gigazine.net/news/20190801-pablo-basque-minipassion/ [17] https://news.yahoo.co.jp/articles/09e31317d0c351bf6d9079b1bc89fdcad95c8a58 [18] https://hayarimon.jp/seven-eleven-mont-blanc-wafu-parfait-basque-cheese-cake-8413/ [19] https://more.hpplus.jp/odekake/gourmet/50813 [20] https://www.atpress.ne.jp/news/240984 [21] https://www.rbbtoday.com/release/dreamnews/20210222/584199.html [22] https://www.dreamnews.jp/press/0000232289/ [23] https://www.iza.ne.jp/article/20200715-G47HBTMNIJN4RMOIQLVYVHNAAA/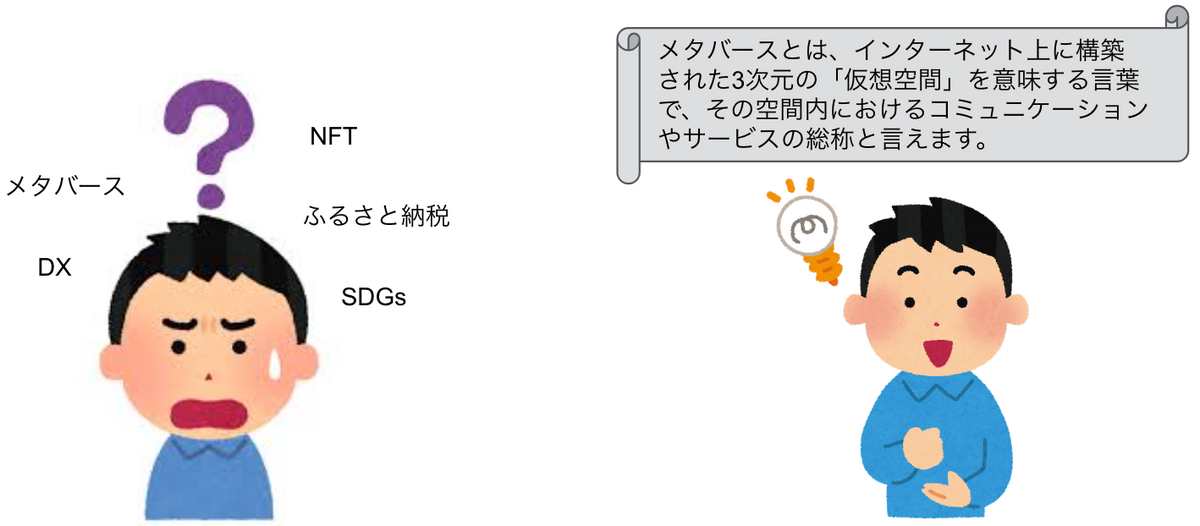
はじめに
自然言語処理とは

構造化事例: 定義文抽出
定義文のニーズ
定義文抽出の流れ
抽出結果
今後の展望
記事の出典