ストックマークでProduct Engineerとして Anews を開発しているiwashiroです。
弊社の開発エンジニアは普段、インフラ・バックエンド・フロントエンド・MLタスクの垣根なくフルスタックに開発しているのですが、今回は普段開発している AnewsのRuby on Railsで構築されているバックエンドアプリケーションに、Sorbetという静的型検査の仕組みを導入し、合わせてCIも整備して継続的な運用をはじめたことについてお話させていただきます。
TL;DR
抱えていた課題
- プロダクトの成長に伴って開発体制も大きくなり、コードベースも複雑さを増す一方で、レビューや動作確認だけでは担保しきれず一定発生してしまう、構文エラー等の見落としに起因するインシデントが増えてきた。
- テストはこれまで比較的書けており、これ以上のテストの拡充で上記のようなニッチなケースもテストでカバーしようとすると、費用対効果の割に品質の担保がしきれない恐れがあった。
取り組み
- 既存のRubyコードに変更を加えることなく、漸進的に静的型検査を導入できるSorbetを導入し、最小限のコストで段階的にコア機能の品質を向上させることを計画した。
- 他の開発メンバーになるべく学習コストをかけないようにしながら、baseブランチは常に型的に整合性の取れた状態を理想として目指し、CIや開発用スクリプトも合わせて整備した。
結果
- 静的型検査の仕組みの導入という当初の目的の達成のほか、非同期に通信するコンポーネント間のインターフェース(I/F)への活用や、IDE等との高い親和性によるDXの向上もあるなど、今までのところ一定の効果が得られている。
Sorbetとは
SorbetはStripe社が開発・公開しているRubyの静的型検査ツールで、Rubyプログラムに静的型検査の仕組みを導入することを目的としています。
特徴
既存Rubyプロジェクトとの高い互換性
Sorbetは通常のRubyのコードに対して100%の互換性があります。加えてファイル単位で型を適用するか、またどの程度厳格なレベルで型を適用するかを決めることが出来るため、既存のRubyプロジェクトに対して漸進的に型を導入することができる設計になっています。
ランタイム時の型検査機構
Sorbetにはランタイム時の型検査機構も備わっており、型のついていないファイルがプロジェクトに混在する場合、静的型検査はパスしても、実行時に発覚する型の不整合からラインタイムエラーが発生する可能性があります。
具体的に言うと、例えばIntergerで型付けされているメソッドの引数があり、静的型検査がパスする場合でも、型のついていないファイルからの呼び出し等でランタイム時にStringが渡って来た場合は、スルーされずにSorbetがランタイムエラーを発生させる、といった挙動が起こります。これは通常のRubyやTypeScriptとは大きく異なる点であり、既存コードにSorbetで型を付けたときには動作確認もしっかり行う必要があることを意味しています。
柔軟な型注釈の表現
Sorbetでは、Rubyのコードに対して型注釈を追加することで型検査を行います。ここでの型注釈とは、変数やメソッドに対して予期される型を明示的に指定することを指しており、具体例としては以下のようなものがあります。
# typed: true
require 'sorbet-runtime'
class Example
extend T::Sig
sig { params(x: String).returns(Integer) }
def self.main(x)
x.length
end
sig { returns(Integer) }
def no_params
42
end
end
Example.main('hello') # => 5
上記の例のポイントを一つずつ見ていきます。
# typed: trueは、このファイルに型検査を有効にすることを示しています。T::Sigモジュールは、メソッドの型を指定するためのメソッドsigを提供します。sigメソッドは、メソッドの型を指定するためのメソッドです。paramsメソッドは、メソッドの引数の型を指定し、returnsメソッドは、メソッドの戻り値の型を指定します。StringやIntegerの箇所には、指定したい型の種類を記述します。
上記を組み合わせることで、main メソッドは、引数 x が String 型、つまり文字列であることを期待し、戻り値が Integer 型、つまり整数であることを期待しています。同様に、no_params メソッドは、引数がなく、戻り値が Integer 型であることを期待しています。
試しにIDEのリアルタイム検査が有効な状態で最後の実行文をExample.main(42)に変更してみると、以下のようなエラーが表示されます。
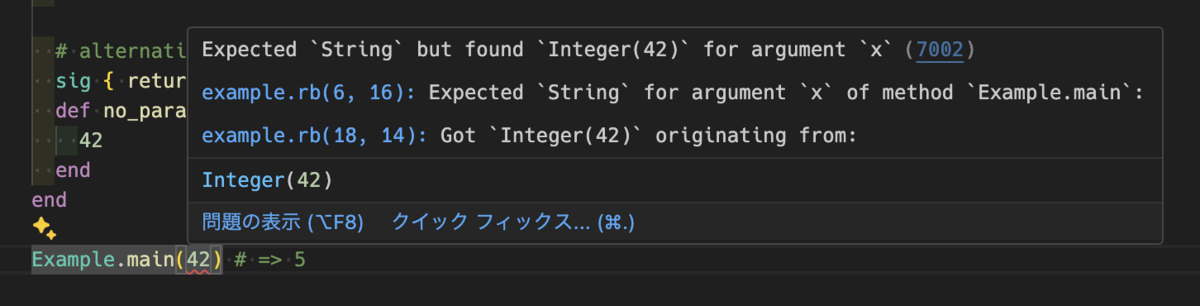
また、存在しないメソッドを呼び出そうとしたり
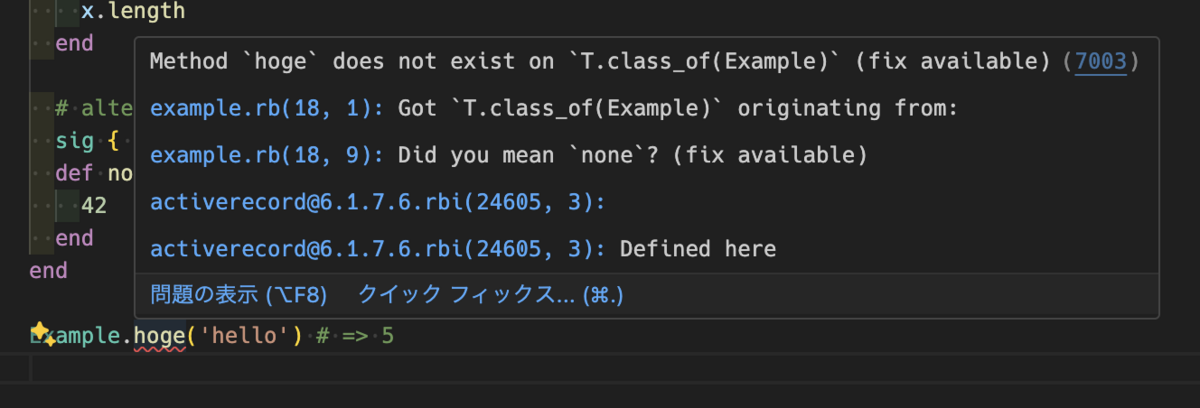
インスタンスからクラスメソッドを呼び出そうとしたり
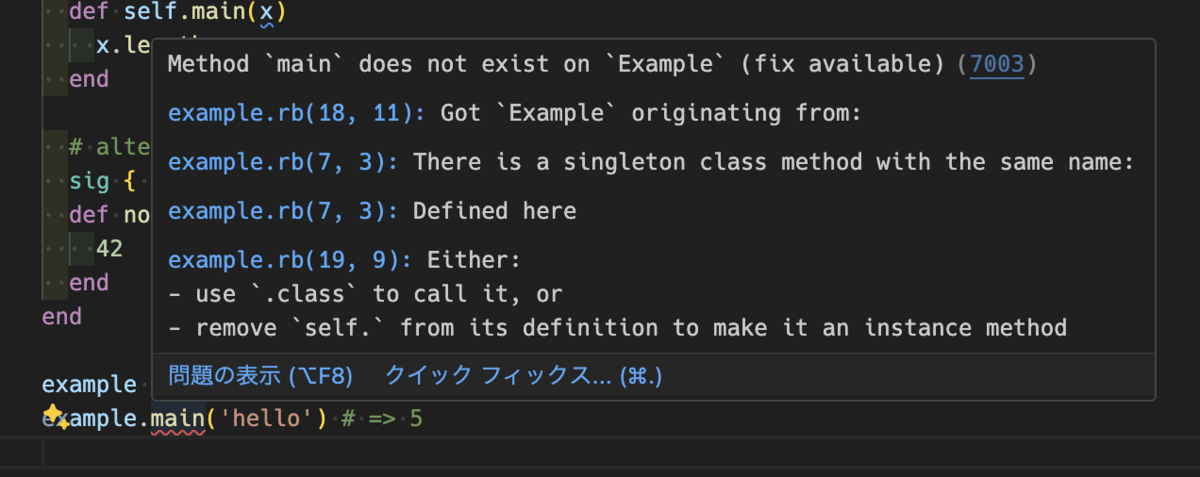
といった場合でもエラーが表示されます。
またsigを用いたメソッドの入出力への型注釈のほか、メソッド内で使用する変数等にも個別に型を付けることが可能です。
# typed: true
require 'sorbet-runtime'
class Example
extend T::Sig
def self.untyped_hash
# T::Hash[T.untyped, T.untyped])という、key, valueともに任意の値を取れるhashに対応する型が推論される
untyped_hash = {}
untyped_hash['a'] = 1 # OK
untyped_hash[:b] = 1 # OK
untyped_hash['b'] = '1' # OK
untyped_hash
end
def self.typed_hash
# T::Hash[String, Integer]という、keyがString, valueがIntegerであるhashに対応する型が明示される
typed_hash = T.let({}, T::Hash[String, Integer])
typed_hash['a'] = 1 # OK
# typed_hash[:b] = 1 # NG: Expected `String` but found `Symbol(:b)` for argument `arg0`7002
# typed_hash['b'] = '1' # NG: Expected `Integer` but found `String("2")` for argument `arg1`7002
typed_hash
end
# 同じ型をコード内で複数回用いたい時はその型をT::Hash[String, Integer]という型エイリアスとして定義できる
TypedHash = T.type_alias { T::Hash[String, T::Boolean] }
# 定義した型エイリアスを使って型を指定
sig { returns(TypedHash) }
def self.typed_hash_with_type_alias
typed_hash = T.let({}, TypedHash)
typed_hash['a'] = true
typed_hash['b'] = false
typed_hash
end
# より詳細に型を指定する場合には、T::Structを継承したClassを用いることで表現できる。jsonへのserialize/deserializeもでき、異なるプロセス間のコンポーネントのI/Fにも利用できる
class TypedParams < T::Struct
prop :user_ids, T::Array[Integer]
prop :is_test, T::Boolean, default: false
end
sig { params(params: TypedParams).void }
def self.typed_params(params)
if params.is_test
puts 'test'
else
puts params.user_ids
# puts params.hoge # NG: Method `hoge` does not exist on `Example::TypedParams`
end
end
end
これ以外にもここでは紹介しきれないほどの多種多様な型の表現方法と活用方法があるのですが、ここでの説明は以上とさせていただき、もう少し詳細が知りたい場合は以下の公式ドキュメントページなどを参照していただければと思います。
IDE等との高い親和性によるリアルタイムなフィードバック
SorbetはエディタやIDEと統合することでリアルタイムに型エラーを検出し、オートコンプリートやエディタ内ドキュメントや定義元へのジャンプといった形でフィードバックを提供します。これにより、開発者は詳細かつ迅速なデバッグが可能となり、DX(Developer Experience)が向上します(大事)。 特にVSCodeについては公式ドキュメントに専用ページが用意されています。他のエディタについては、公式ドキュメント - Editor Featuresページをご参照ください。
導入
弊社では、AnewsのバックエンドアプリケーションにRuby on Railsを採用しているのですが、プロジェクト立ち上げ当初から比べると最近は開発体制も大きくなり、シンプルな設計を心がけてはいてもコードベースの複雑さも増す一方でありました。こうなってくると自然、レビューや動作確認だけでは担保しきれず一定発生してしまう、構文エラー等の見落としに起因するインシデントが増えてきていました。
ポストモーテムでは、恒久案としてテストをこれまで以上に拡充することがよく上がっていたのですが、これまでもテストは比較的書けており、上記のようなニッチなケースもテストでカバーしようとすると、費用対効果の割に品質の担保がしきれない恐れがあると個人的には考えていました。そこで、テストに比べてもっと抜本的に機械的に不具合を検知する仕組みとして、上述のように、既存のRubyコードに変更を加えることなく漸進的に静的型検査を導入できるSorbetを導入し、最小限のコストで段階的にコア機能の品質を向上させることを検討しました。
単に仕組みを導入するだけなら、公式ドキュメントのAdopting Sorbet in an Existing Codebaseを参照すれば大丈夫でした。 簡単にこの中でやっていること + 私たちのプロジェクトで追加で対応したことを紹介させていただきますので、補足として参考にしていただければと思います。
gemの追加
導入にあたっては、sorbet, sorbet-runtime, tapioca というgemを追加します。
sorbet, sorbet-runtimeはSorbetの型検査機能の本体となるgemで、tapiocaはgemやdslの型情報ファイルを自動生成し、Sorbetがそれらを利用して正確な型検査を行えるようにするためのgemです。
なお、特徴のセクションでは触れなかったのですが、Sorbetでは必ずしも実装と型をセットにして定義する必要はありません。例えば、gemで定義されているクラスのメソッドなどの定義時に型を付けることができないメソッドに対しては、*.rbiという形式のファイルを用いて、型情報のみを別の場所から提供することができます。tapiocaは、それらの型情報ファイルを自動で生成し管理することができます。 なお、tapiocaが生成するファイルはすべてコードベースのcommit対象のファイルとして管理します。tapiocaを用いたrbiファイルの管理については、公式ドキュメントRBI Filesページを参照してください。
tapiocaの初期化
bundle exec tapioca initでtapiocaがrbiファイルを格納するディレクトリを初期化します。
また、わたしたちのプロジェクトではrailsを利用していたため、bin/tapioca dslを実行して、sorbet/rbi/dsl配下にもrbiファイルを自動生成しました。
合わせて、sorbet/configに型検査の対象外としたいファイルやディレクトリを追加しておきました。
srb tcの初回実行
bundle exec srb tcを実行し、発生するエラーを確認します。次に、型検査が通るまで一つずつこのエラーへの修正を繰り返します。わたしたちのプロジェクトでは主に以下のようなことに対応しました。
未定義エラーへの対応
tapiocaによって自動生成されたrbiファイルだけでは、一部moduleやclassの定義が見つからずにエラー(以下、未定義エラー)が発生していました。ただtapiocaにはそれを解消できるbin/tapioca todoコマンドが用意されているので、これによって生成されるsorbet/rbi/todo.rbiで、ある程度このエラーを解消しました。ただ注意点としては、これでもまだ未定義エラーが発生し、型検査が通らない場合があるので、その場合は、手動でrbiファイルを作成する必要があります。手動で作成する場合はGitHub - RBI files for missing constants and methodsに沿って作成していくのですが、わたしたちのプロジェクトでは単に未定義エラーを解消できれば充分であったので、sorbet/rbi/todo.rbiと同階層にunresolved_constants.rbiを作成し、同じ形式で未定義エラーとなっているmoduleやclassを管理することとしました。
ただ1点注意点があり、bin/tapioca todoは現在非推奨コマンドとなっており今後のバージョンで削除される予定です。そのため今後は手動でこれらのrbiファイルを作成し、メンテナンスすることが推奨されています。
わたしたちのプロジェクトでは、sorbet/rbi/todo.rbiの内容はすべてunresolved_constants.rbiに移行し、sorbet/rbi/shimsというフォルダの直下に置くようにしました。
↑
2024/07/19修正:
GitHub - tapioca Configurationに従い、sorbet/rbi/shims/todo.rbiとして配置し、sorbet/tapioca/config.ymlのtodoセクションに記載するようにしました。
shimsフォルダは、自前で生成した型ファイルを格納するためのフォルダです。railsのmodelsなどで型を分けて付ける必要があるときなどには、このフォルダにapps以下のディレクトリ構造を再現してrbiファイルを作成し、型を定義していくことになります。
参考: GitHub - RBI files for missing constants and methods
重複定義エラーへの対応
使用するライブラリの組み合わせによっては、メソッドの重複定義が発生し、エラーが発生することがあります。 本来であれば、エラーにあるとおりに解決するのが望ましいのですが、わたしたちのプロジェクトでは単にエラーを解消できれば充分であったので、そのような重複定義されているメソッドを一時的にコメントアウトすることでエラーを解消しました。 なお、後述のCI構築のセクションで触れたいのですが、このコメントアウトはスクリプトによる自動化を行い、型ファイルの自動更新時に合わせて実行されるようにしています。
CI構築
上述の導入まで完了したのち、デフォルトブランチでは常に実装に対して整合性の取れた型が自動生成によって保たれるように、CIをGitHub Actionsで整備しました。このことによって、普段通り実装をするだけでも自然と最低限の型のメンテナンスが行われるようになり、開発者は型のメンテナンスに対して意識を向ける必要がない、という状況を実現しました。
整備したCIでは、以下のことを行っています
型の検証
gemの型ファイルの検証
bin/tapioca gem -V --verifyを実行して、sorbet/rbi/gems以下で管理している型ファイルを検証し、gemの更新によって型ファイルが合わせて更新されているかを確認します。ここでエラーが発生した場合は、対応する型ファイルを更新するように促します。
対応する更新用のMakeコマンドも用意しており、実行するとbin/tapioca requireとbin/tapioca gemが実行されるようになっています。これによってsorbet/rbi/gems以下で管理している型ファイルが適切に自動更新されるようになっています。
各コマンドの詳細については、GitHub - Manually requiring parts of a gemを参照してください。
dslの型ファイルの検証
bin/tapioca dsl --verifyを実行して、sorbet/rbi/dsl以下で管理している型ファイルを検証し、schemaの更新等に合わせて型ファイルも更新されているかを確認します。ここでエラーが発生した場合は、対応する型ファイルを更新するように促します。
なお、bin/tapioca dsl --verifyでは、bin/tapioca dslのよる自動出力の結果と差分があるかを見ているため、事前にコメントアウトしている重複定義メソッドのコメントアウトを解除する必要がありました。加えて、開発用端末のOSとCI実行環境のOSの差異によっては、perftoolsに関する型ファイルに差分がありCIが落ちることがあったのですが、機能に影響を与えない差分であるため、CIでは無視するようにしています。
こちらも対応する更新用のMakeコマンドを用意しており、実行するとbin/tapioca dslによる型の自動更新を行い、その後に重複定義メソッドのコメントアウトを実行するようになっています。
shimsの型ファイルの検証
bin/tapioca check-shims -Vを実行して、sorbet/rbi/shims以下で管理している手動で作成した型ファイルを検証しています。ここでエラーが発生した場合は、型ファイルを更新するように促します。
静的型検査の実行
上記の型の検証をneedsのjobとして設定し、それが成功した場合にbundle exec srb tcによって静的型検査を実行します。
開発用コマンドの整備
上述のCIによって型の検証が行われるようになったことで、開発者は手動で型のメンテナンス自体を意識する必要がなくなりましたが、開発時に任意に型の検証を行いたい場合などに備え、いくつかのmakeコマンドを整備しました。
bundle exec srb tcを実行する静的型検査の実行コマンド。- gemの型ファイルの更新コマンド。
- dslの型ファイルの更新コマンド。
- gemとdslの型ファイルの一括更新コマンド。
- CIと同様の手順で型ファイルの検証を行うコマンド。
bundle installの実行と、そのあとにgemの型ファイルを更新するコマンド。
また、db:migrateとdb:rollback時には、dslの型ファイルを更新を実行するRake taskを整備しました。
まとめ
今回は、Ruby on Railsのバックエンドアプリケーションに静的型検査のSorbetを導入し、それについてのCIを整備して継続的な運用をはじめた話をお話ししました。 これまでに述べてきた取り組みによって、これまでの開発体験と大きく変わりなく、漸進的に型検査を導入することができました。 今後は、型が適用されているファイルを拡充し、型のレベルもファイルごとにより厳格にしていきたいなと考えています。
ここまでお読みいただき、ありがとうございました!
開発メンバー募集中です
Stockmarkでは一緒にプロダクトと組織を成長させていただける方を広く募集しています カジュアル面談からぜひお気軽にご連絡ください。